

- cross-posted to:
- selfhosted@lemmy.world
- cross-posted to:
- selfhosted@lemmy.world
This is the post on reddit: https://www.reddit.com/r/selfhosted/comments/1myldh3/i_built_youtubarr_the_sonarr_for_youtube/
looks cool I have been wanting something like this for a while
You must log in or register to comment.
They have a whole list of these in the linked Readme. Thanks for posting - I was considering setting up pinchflat but this might be a lot lighter on resources.
My use case: I would like to run something like this, but either directly on, or syncing to my laptop. I don’t watch much YouTube, but it would be nice to have stuff to watch offline, and cut google out of all the behavioural metadata.
Take a look at ytdl-sub if you want light weight. I load the resulting videos into jellyfin as series.
It’s based on yt-dlp, which I can’t seem to get working reliably with my VPN, even with manual intervention like using cookies from a browser, switching servers, etc. Guess VPN IPs hit the rate limits pretty regularly, though I don’t want to risk my real IP getting banned. I’ve seen some people suggest using a VPS, but sounds like a lot of effort. Running something like this on a server and expecting it to reliably download videos in the background isn’t going to work that well from my experience.
Sadly no actual search function that pipes it into yt-dlp.
Imagine the releases were done as yearly seasons and their individual videos.I’ve been using Metube but it’s pretty basic. Might give this a shot.
Not exactly ideal archival software…
It doesn’t store files in a human readable way and requires a separate DB and application to interpret your stored data. Without controls over how it stores that data.
Surely, you meant https://github.com/kieraneglin/pinchflat
Whats you personal experience of pinchflat vs tubearchivist?
Pinchflat is way less complicated than TubeArchivist and integrated with Plex without any extra work.
Surely, you meant https://github.com/meeb/tubesync
Sonarr is based on RSS feeds - explicitly designed for this purpose of getting new updates from subscription-like sources. This is much lighter in processing requirements. I’ve also tried to make this UI as similar as possible to the other *arr apps for familiarity.
Index an entire channel/playlist or get “older” videos. Subarr’s RSS approach is specifically for “subscriptions”: new video is posted, take some action Media management. Once Subarr kicks off the post-processor (like yt-dlp), its job is done. Use Plex/Jellyfin/etc or another one of the linked solutions above if you require more control over your media
this naming trend needs to die
aislopmukangarr
Why? It’s a brand at this point and lets you know exactly what its about.
There’s more *arr tools that aren’t aggregator automation tools than there are aggregator automation tools.
Also It was only funny when using an existing words like "sonar, “radar”, “lidar”. Jellyseerr is dumb, even Jackett was pushing it.
I guess it makes it somewhat easier to associate them as part of a group of software, but now we have stuff like Homarr that is entirely unrelated, but still a useful tool.
To be fair, jellyseerr is a fork of overseerr focused on jellyfin, so the name at least makes sense.
I mean it is clear that it’s an aggregator (? Not sure what the right term is for this) but I can’t even begin to count the number of times I access Radarr instead of Sonarr because I forgot which one is for shows or movies.
Prowlarr is way more intuitive at least.
Sonarr is for series - that’s how I remember :-)
But I use Overseer anyway, so I don’t use them often directly.
I mean it is clear that it’s an aggregator
Did you mean aggrrrregator?
Agreed it would be nice if radarr and sonarr were combined into one, but Youtubarr is at least pretty descriptive.
What is a brand? “Sonarr”? Never heard that.
*arr services are well known in the self hosted community
IMO the trouble is that there are so many of the things now that I need a damn flowchart to understand how they work together and which ones I need.
(No, seriously: I want to set up an *arr stack but don’t understand how. Could somebody please send me a flowchart??)
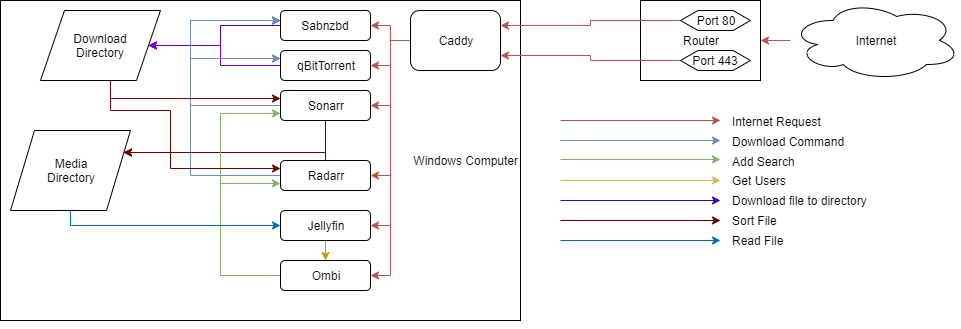
Here’s a very old flow chart I made for some folks that didn’t want to use Linux. Though it mostly applies to any serup
Sorry, I tried but I couldn’t figure out how to use Flowcharr-t.
If you want movies you use Radarr, and if you want TV Shows you use Sonarr. And if you want either of those to use torrent sites to find things rather than Usenet, you setup Prowlarr to convert from those random sites into the format Radarr and Sonarr support.
There are others, but that’s a place to start.
All you actually need are sonarr (tv) radarr (movies) overseer (request management) and prowlarr (indexer management) you don’t actually need the last two.
For the purposes of this explanation sonarr and radarr are the same, but keep in mind that sonarr only does tv shows and radarr only does movies
You tell sonarr what you want to watch --> sonarr tells prowlarr what you want to watch --> prowlarr will search websites for magnet links to your show (you have to specify which websites) --> prowlarr will give the download manager (qbittorrent, etc) the magnet link and it will download it --> sonarr will take the downloaded file and copy it somewhere else for organizational purposes --> media server (jellyfin) will see the copied file and download associated metadata (thumbnail, episode name, episode number, etc) and allow you to watch it
The only programs you need for a purely functional arr stack are sonarr/radarr, prowlarr, qbittorrent, and jellyfin, or any other media server. Anything else is purely icing on the cake
It’s not a flowchart but I would recommend the following site: https://trash-guides.info/
Lots of useful info and guides
ytdl-sub already existed for a while
I leverage pinchflat for this
Just set this up a few days ago and so far am very happy. Ended up choosing it over other options since I wanted something that saves the downloads in a humanly accessible way by simply putting them into channel folders with the video names as title.










{kind=link}